The adoption of voice assistants in home audio applications is growing at a rapid pace, and today's consumers expect a smart, seamless voice user experience coupled with exceptional sound quality from their home audio products, like smart speakers and soundbars. Manufacturers, on the other hand, seek to shorten the development cycle to rapidly deliver differentiating products and capitalize on the growing adoption. However, most product development teams lack the necessary voice expertise or engineering resources required to alleviate the significant challenges involved with developing voice solutions. Delivering a seamless experience with voice assistants requires domain expertise in the development and integration of hardware components such as microphone arrays, loudspeakers, SoCs or digital signal processors, as well as implementation of sophisticated audio processing algorithms on the target hardware. That is why device OEMs prefer to start with an industry standard reference design that can help them rapidly deploy high-performance voice products.
To tackle these unique audio development challenges head-on and mitigate as much risk as possible, DSP Concepts developed a flexible, high performance reference design powered by the QCS400 Smart Audio SoCs. The QCS400 series of audio SoCs are designed specifically to help customers meet the growing demand for smarter speakers, smart home assistants, soundbars and Audio-Video Receivers (AVRs). These SoCs help further support voice UI-enabled smart home ecosystems and meet the converging technology needs of end products that combine audio, connectivity, and display features together. With a rich feature set at an unprecedented level of integration, QCS400 SoCs can help significantly reduce the overall bill of materials (BOM) for complex, feature-rich, voice-supported home audio products at a range of tiers.Here, we will discuss the design components and preliminary decisions an audio developer must make in order to build a robust voice-enabled device based on the joint reference design.
Designing a voice-enabled product starts with the careful selection of hardware and software components to achieve the desired far-field range within the constraints of cost, form factor, and use-case. For example, a smart speaker that needs to pick up commands from across a large living room falls within a far-field range of 6 to 10m, which requires more microphones and sophisticated noise suppression algorithms. Moreover, if the same device also needs to deliver premium audio quality, it must have multiple loudspeakers integrated within to provide that premium surround sound experience.
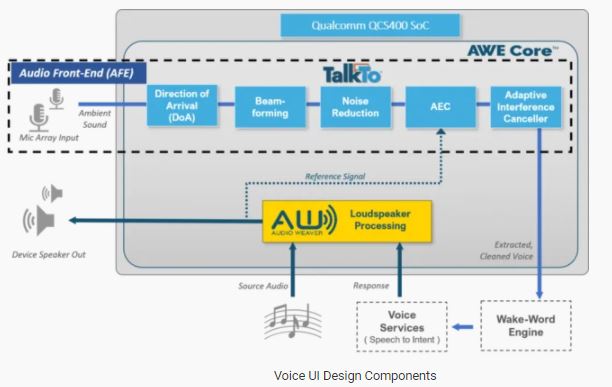
We have all had the experience of using a smart assistant and the frustration involved in repeating the voice query, particularly in noisy environmental conditions. Irrespective of form factor or cost, consumers expect a consistent experience when using voice-enabled products, which requires that it operate seamlessly from any location and regardless of whatever external noise is in the environment. There are many different algorithms at work in these always-listening devices to achieve that, all of which must be tuned to suit the product's design and application. The blocks involved in a typical always-listening system are shown in Figure 1 below.
Microphone Array: Voice activation systems require one or more microphones working in tandem to capture the incoming signal that is passed on to the Audio Front-End (AFE) algorithms. Size, cost, performance, and reliability are the primary factors to consider when selecting the microphone array, and the performance of that array hinges on the number of microphones, geometry, and placement on the device. The combined multi-mic signal from the microphone array improves the effective SNR available for signal processing in the rest of the audio signal chain.
Audio Front-End (AFE): The AFE processes the multi-channel microphone array signal to cancel any interfering background noises or the device's own playback signal. The resulting clean signal is then sent to the wake-word detection engine to reliably recognize the wake word such as Alexa, OK Google, etc. that is pre-programmed on the device. The AFE can involve multiple signal processing algorithms, which are outlined below, to effectively cancel out unwanted interference signals while preserving user speech.
Direction of Arrival (DoA) Detection: DoA detection determines the position of the user relative to the product so the microphone array can steer the beam in the direction of the user's voice.
Beamformer: The Beamformer accepts sounds coming from the determined direction of arrival while rejecting sounds from other directions. The performance of the beamformer depends heavily on the microphone array geometry, beam width, background noise level, and the effective SNR of the microphone array.
Acoustic Echo Canceller (AEC): The AEC rejects the playback signal on the device speaker to pick up the user's voice command. The more echo cancellation, the better voice activation performance. Algorithms that can cancel out 30 to 40 dB of echo during a music barge-in scenario typically provide improved detection accuracies, particularly at low frequencies and loud playback levels. In general, developers have to compromise low-frequency sound quality to achieve higher detection rates during music playback, even more so in low-cost, small form factor devices.
Adaptive Interference Canceler (AIC): AIC algorithm rejects interfering sounds that are difficult to cancel out with a traditional beamformer, such as a TV playing in the living room or microwave noise in the kitchen. Unlike other adaptive cancellation techniques, DSP Concepts' AIC algorithm does not require a reference signal to cancel out the interfering noises. Instead, it uses a combination of beamforming, adaptive signal processing, and machine learning to cancel out up to 30 dB of interference noise while also preserving the desired speech signal. An AIC is necessary for smart speakers that are typically used in living room environments where there are interfering noises and moderate to high reverb conditions.
Wake-word detection: The resulting clean voice from the AFE is compared to a wake word utterance, such as "Alexa", to detect the presence of that wake word. A wake-word detection algorithm is usually a machine learning model, the size of which will also impact the detection performance. For example, a small model that is 64 KB in size will be less accurate than a large model that's 1MB in size and is trained on a significantly larger amount of data. A wall-powered smart speaker typically only processes the wake word on the device itself, while the actual command processing is offloaded to the cloud server.
All the advanced processing described above can also be generalized and ported to portable, battery-operated voice assistant products, albeit with an additional battery life constraint that requires further optimization. In order to achieve battery life improvements, portable devices typically include an activation mechanism at the front end to wake up the device only when a user command is detected. This works because one of the microphones in the array is always on and always listening for speech activity, which is enough to wake up the processor only when the incoming signal exceeds a pre-set energy threshold.
Microphone Selection
Microphone selection can be a challenging aspect of voice-enabled product design for beginners. Developers should always adhere to the following design guidelines when selecting a microphone that goes into the arrays for smart speaker and soundbar products:
Optimal Microphone Array Geometries
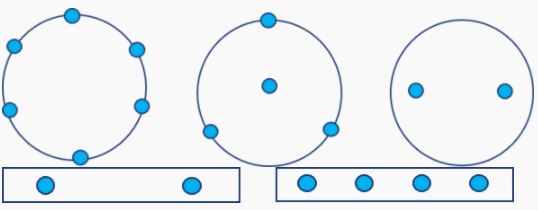
The required microphone array geometry for a specific product depends on the device location and directionality relative to the user. For example, a smart speaker that requires a 360-degree field of operation requires a circular array. Large microphone spacing also improves the far-field performance of the device. Increasing the microphone spacing in an array increases time differences between signals and leads to improved far-field performance.
Our tests have shown that placing microphones on a circle measuring 70mm in diameter is generally the best choice for a 3 to 6-mic array. For low-cost, small form factor devices, we recommend spacing in the 40 to 70 mm range but size constrained products can also go down as low as 20 mm. In our state-of-the-art test labs at DSP Concepts, we have tested multiple microphone array configurations that impact the voice UI performance for home audio products. Our test results indicate that a 4-mic Trillium configuration shown in the figures below offers the best trade-off between far-field performance and cost, particularly for smart speaker and sound bar products.
Processor Selection
Selection of an SoC or a digital signal processor (DSP) is also crucial to the design of a voice UI system. The selected processor architecture should have enough CPU processing power and a large enough memory footprint to fit the audio algorithms as well as the wake word model. Qualcomm QCS400 series chipsets offer an ideal solution for home audio products with support for multi-core architectures, as well as flexible processor power architectures to enable wall-powered as well as battery-powered products.
DSP Concepts has incorporated its proprietary TalkTo suite of algorithms in 2, 4, and 6-mic configurations that are optimized for the CPU resource and memory requirements of the Cortex-A53 core on the QCS400 reference solution. These designs support a wide variety of form factors from low-cost devices to high-performance product designs, and the algorithms are tuned to meet Amazon Alexa Voice Service (AVS) 2.1 premium requirements to deliver out-of-the-box premium capabilities and reduce certification costs for OEMs. Moreover, the leadership of Qualcomm Technologies, Inc. in low-power, high-performance chipsets, with integrated connectivity solutions like Bluetooth, provides a comprehensive platform while helping to significantly reduce the development time and complexity in smart speaker and sound bar designs for a wide range of OEM tiers.
Conclusion
Adoption of voice assistants in home audio products is only going to increase in the near future. Smart speakers and soundbars are a perfect home for the voice assistants. A standardized reference design such as the QCS400 design that can provide out-of-the-box implementation of voice assistant features, can significantly expedite the product development cycle and help reduce the cost and time to commercialization of audio product lines.
Key features of use case:
